した。使用した回答数は134,840件である。景気ウォッチャー調査には、例えば以下のような回答が含まれる。
「2020年1月;近畿;その他非製造業〔衣服卸〕(経営者);・最近の新型コロナウイルスの悪影響も懸念されるが、既に中国政府の発表で、中国からの輸出の減少がしばらく続くことが予想される。これに伴い、納期の遅れや、販売時期の繰り下げといった、実質的な影響や混乱が生じつつある。業界では、悪い材料が多過ぎるとの見方が大半を占める。;□」
この「□」は5段階で評価する「景気の現状に対する判断(方向性)」・「景気の先行きに対する判断(方向性)」を表し、本コラムでは、景気の現状及び先行きを良いと判断する順に「◎」を5、「○」を4、「□」を3、「▲」を2、「×」を1といった数値に変換して扱う。
テキストデータは表形式でまとまっている構造化データとは異なり、元の非構造化状態のままでの分析が困難である。そのため本コラムでは、大規模言語モデルの一つである「claude-3-5-sonnet-20241022 30 」を活用し、因果表現のペアを抽出した。その抽出例を示したコラム1-1-5①図を見ると、元の回答から因果表現がネットワークとしてまとまっていることが確認できる 31 。
コラム 1-1-5①図 大規模言語モデルを用いた因果関係の抽出例
| 原因 | 結果 |
|---|---|
| 最近の新型コロナウイルスの悪影響も懸念 | 業界では、悪い材料が多過ぎるとの見方が大半 |
| 中国からの輸出の減少がしばらく続くことが予想 | 納期の遅れ |
| 中国からの輸出の減少がしばらく続くことが予想 | 販売時期の繰り下げ |
| 納期の遅れ | 実質的な影響や混乱が生じつつある |
| 販売時期の繰り下げ | 実質的な影響や混乱が生じつつある |
| 実質的な影響や混乱が生じつつある | 業界では、悪い材料が多過ぎるとの見方が大半 |
| 業界では、悪い材料が多過ぎるとの見方が大半 | 3 |
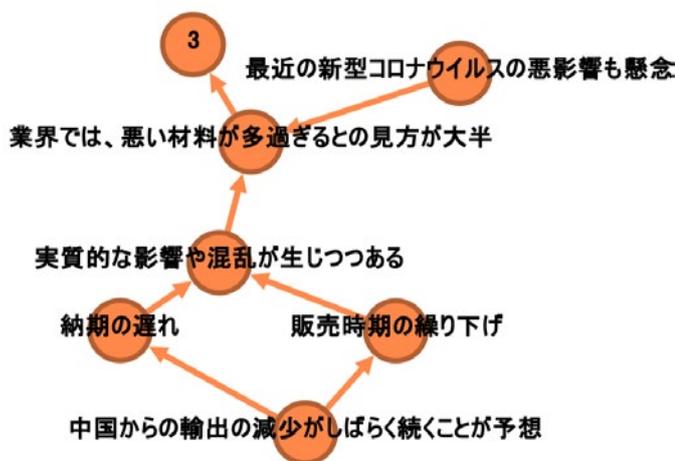
資料:内閣府「景気ウォッチャー調査」より中小企業庁作成
(注)右の図は、左の表をネットワークとして可視化したもの。矢印は因果関係を表している。
抽出した表現をそのままネットワーク分析に用いることも可能だが、例えば「レストラン関連はディナー利用が伸び悩んでいる」、「レストランのディナー帯の利用が伸び悩む」などは同じ意味としてまとめることで、複数の回答のつなぎ合わせがより有用となる。この処理について最も簡単な方法は、Matsuoka et al. (2024) で示されているように、各表現を文埋め込みによってベクトル表現に変換し、k-平均法 32 やノイズを含むアプリケーションのための密度に基づく空間クラスタリング(Density-Based Spatial Clustering of Applications with Noise、以
30 GPT-4oとClaudeのそれぞれの抽出結果を比較したところ、後者の方が精度が高かったため、本コラムではClaudeを採用した。
31 本稿の作成においては、久野遼平氏(中小企業庁事業環境部調査室、東京大学大学院情報理工学系研究科講師)が中心となって分析作業を行った。実際のプロンプトでは因果表現以外も抜き出しており、ここでは扱っていないが、今回の分析で使用した正確なプロンプトなどは、以下の「GitHub」にて久野氏が整理・公開している(外部サイト: https://github.com/hisanor013/HierarchicalNarratives )。
32 「k-平均法」は、各グループの中心点となるk個のデータを選び、各データを最も近い中心点のグループに割り当ててことで、類似したデータをk個のグループに分類する手法である。